
- July 1, 2024
- 0 Comments
- By geek1707@gmail.com
Introduction to Large Language Models: Revolutionizing Natural Language
Processing
The advent of large language models (LLMs) has marked a revolutionary leap in the field of artificial intelligence, particularly within the domain of natural language processing (NLP). These models, characterized by their vast scale and profound complexity, have transformed how machines understand and generate human-like text, making significant strides in tasks ranging from translation and summarization to content generation and conversation.
Background
The journey of NLP began with rule-based systems, which were later superseded by statistical methods during the late 20th century. The introduction of neural network-based models brought about significant improvements, with deep learning models becoming the de facto standard due to their ability to learn complex patterns from large amounts of data. However, the true transformative change came with the development of models such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), which utilize the transformer architecture—a model reliant solely on attention mechanisms, devoid of recurrence and convolutions, to process data.
The transformer model, introduced by Vaswani et al. in the seminal paper “Attention Is All You Need”, laid the groundwork for the current generation of LLMs. This architecture allows for significantly more parallelizable computation, which is crucial given the enormity of the datasets used for training these models. The key innovation of the transformer is the self-attention mechanism that computes the relevance of different parts of the input data, allowing the model to focus on important features and ignore the rest.
Purpose of the Survey
This survey aims to delve deep into the architecture, functionality, and applications of large language models. By comparing models like GPT-4, Claude 2, and Llama 3, we explore their capabilities, benchmark performance across various NLP tasks, and discuss their broader impacts on technology and society. Additionally, this survey will address the technical and ethical challenges posed by these models, highlighting ongoing debates about data bias, model transparency, and environmental sustainability. Through this comprehensive analysis, the survey intends to provide a holistic view of the state-of-the-art in large language models, aiding stakeholders from academia to industry in understanding and leveraging these powerful tools effectively.
This introduction sets the stage for a detailed exploration of these transformative models, charting their evolution, the theoretical underpinnings of their design, and their profound implications across various sectors.
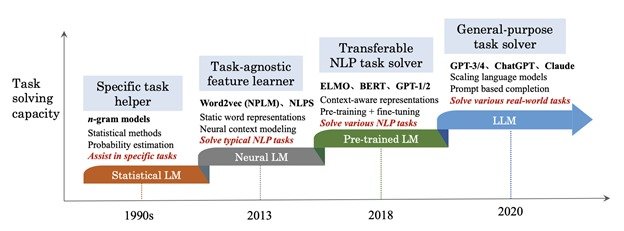
Evolution of Large Language Models
The evolution of large language models (LLMs) is a compelling narrative of incremental advancements and breakthrough innovations that have significantly reshaped the landscape of natural language processing (NLP). This section traces the trajectory from early statistical models to the sophisticated architectures in use today, highlighting key developments and their impact on the field.
Early Development
The initial phase of NLP was dominated by rule-based systems, which relied heavily on handcrafted rules to process text. These systems were rigid, often struggling with the complexity and variability of natural language. The limitations of rule-based systems led to the adoption of statistical methods in the 1980s and 1990s, which marked the first significant evolution in NLP. Statistical models, including Hidden Markov Models (HMMs) and later, n-gram models, leveraged large corpora for language modeling, relying on the statistical properties of language rather than explicit rules.
Breakthroughs in Neural Networks
The introduction of neural networks, particularly Recurrent Neural Networks (RNNs), shifted the paradigm by enabling models to learn and predict sequences of words, thus capturing temporal dependencies within text. However, RNNs and their variants, such as Long Short-Term Memory (LSTM) networks, were often hampered by challenges such as difficulty in training and the vanishing gradient problem, which affected their ability to learn long-range dependencies.
The breakthrough came with the introduction of the transformer model by Vaswani et al. in their pivotal paper, “Attention Is All You Need”. The transformer model eschewed recurrence entirely in favor of attention mechanisms—components that process words in parallel while dynamically focusing on different parts of a sentence. This model architecture significantly improved the efficiency and effectiveness of training deep neural networks for NLP by enabling more direct learning of long-range dependencies and reducing training times.
Transformer Models and Beyond
The success of the transformer architecture catalyzed the development of various LLMs. Notably, OpenAI’s GPT (Generative Pre-trained Transformer) models and Google’s BERT (Bidirectional Encoder Representations from Transformers) leveraged this architecture to achieve remarkable performance gains across a range of NLP tasks. GPT models, starting from GPT and evolving through GPT-2 to GPT-3 and the latest GPT-4, utilized transformers in a scaled-up setting, training on increasingly vast datasets and achieving unprecedented levels of fluency and generalization capabilities.
BERT introduced a novel approach of bidirectional training, which was a departure from the unidirectional or sequential training typical in previous models. This allowed the model to integrate a more profound understanding of language context and nuance, setting new standards for tasks like question answering and language inference.
Impact on NLP and Broader Implications
The evolution of these models has not only pushed the boundaries of what machines can achieve in understanding and generating human-like text but has also opened up new possibilities for applications in areas such as automated content creation, real-time translation, and personalized communication assistants. Moreover, the principles underlying transformer models have spurred innovations in other areas of artificial intelligence, influencing the development of models capable of handling more complex tasks beyond text, including image and multi-modal data processing.
The rapid evolution of LLMs encapsulates a journey from rudimentary text processing algorithms to sophisticated systems that can mimic human-like understanding and generation of natural language. This progression underscores the transformative impact of machine learning on NLP, setting the stage for future innovations that could further revolutionize how we interact with technology.


Leave a comment